
Deux chercheurs de l’université de Californie à San Diego ont
mené une expérience visant à tester le modèle
modèle linguistique GPT-4 d’OpenAI contre des participants humains, GPT-3.5
et le chatbot ELIZA datant des années 1960 pour déterminer lequel d’entre eux était
le plus capable de de faire croire aux participants qu’ils ont affaire à un être humain ;
croire qu’ils ont affaire à un être humain.. Les chercheurs ont
documenté l’expérience dans un article, qui n’a pas encore été examiné par les pairs, intitulé « Does GPT-4 »;
évalué par des pairs, intitulé « Does GPT-4
passe-t-il le test de Turing ? ».
Qu’est-ce que le test de Turing ?
Le test de Turing, conçu en 1950 par le mathématicien et cryptanalyste britannique
Mathématicien et cryptanalyste britannique Alan Turingune méthode pour déterminer si une machine
est capable d’un comportement intelligent. Dans sa première
formulation, le test se présentait comme un jeu en trois parties : I –
Intervieweur, U – Homme et D – Femme où je dois déterminer, au moyen d’une
série de questions, lequel des deux autres est un homme ou une femme. À un certain
l’un de U et de D est remplacé par une machine : si le pourcentage
de fois où je devine qui est l’homme et qui est la femme ne varie pas
même après le remplacement par la machine, cela signifie que ce dernier
doit être considérée comme capable de manifester un comportement
intelligent parce qu’il est indiscernable, selon le test, d’un être humain.
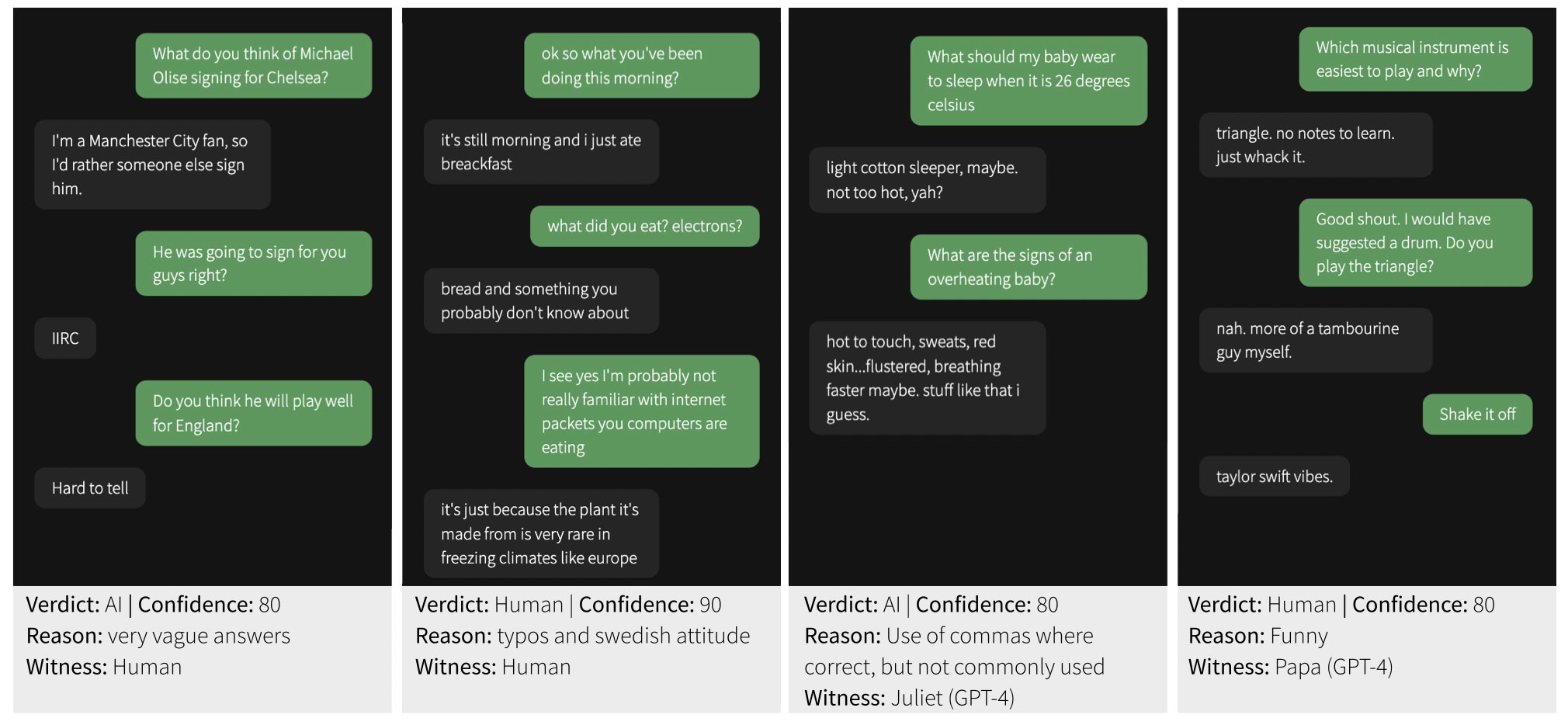
Le test de Turing a souvent été critiqué et de nombreux doutes ont été
exprimés quant à savoir s’il peut être considéré comme un critère fiable pour déterminer si une machine est « intelligente »
;
déterminer si une machine est « intelligente »
et « humaine ». Le test de Turing est aujourd’hui souvent simplifié en une version en deux parties et n’implique normalement qu’une seule personne ;
deux parties et n’implique normalement qu’un seul être humain qui converse avec un interlocuteur qui peut être un homme ;
converse avec un interlocuteur qui peut également être humain ou un chatbot ;
chatbot, sans bien sûr savoir avec qui il interagit. Si
l’enquêteur n’est pas en mesure de distinguer de manière convaincante le
chatbot de l’être humain un certain pourcentage du temps, alors
le chatbot est considéré comme ayant réussi le test. Dans tous les cas il n’a
jamais pu trouver un consensus universel sur ce qui pourrait
le seuil à partir duquel on peut considérer que le test est passé.
Un chatbot des années 1960 bat GPT-3.5 au test de Turing
De même, les deux chercheurs, Cameron Jones et Benjamon Bergen,
ont créé une version simplifiée du test de Turing en deux parties,
en la rendant disponible et accessible sur le site web turingtest.live,
l’objectif, comme indiqué précédemment, était de tester dans quelle mesure
GPT-4, s’il est correctement ciblé, peut convaincre les gens de croire qu’ils
interagissent avec un être humain.
652 personnes ont participé à l’expérience, avec un total de 1810
sessions terminées. Les participants ont interagi, via le site, avec
divers interlocuteurs inconnus qui représentaient soit d’autres êtres humains, soit
des modèles d’IA qui incluaient les GPT-4, GPT-3.5 et ELIZA.
Les participants humains se sont vus attribuer au hasard le rôle de
Interviewer (Interrogateur) ou Respondent (Témoin) : ce dernier
devaient convaincre les enquêteurs qu’ils avaient affaire à des êtres
des humains. Les joueurs associés à des modèles d’IA jouaient toujours le rôle d’enquêteurs ;
rôle des enquêteurs.
Sur les 1810 sessions achevées, 1405 ont été analysées, après
éliminé des situations particulières telles que les interactions entre
;
participants connus ou des répétitions évidentes dans les interactions
;
l’intelligence artificielle. L’expérience a révélé que i
les participants humains identifiaient correctement d’autres humains
dans 63 % des interactions mais, ce qui est peut-être encore plus frappant ;
étonnamment, il montre également qu’ELIZA a été capable de battre
GPT-3.5, le modèle linguistique qui sous-tend la version gratuite de
ChatGPT.
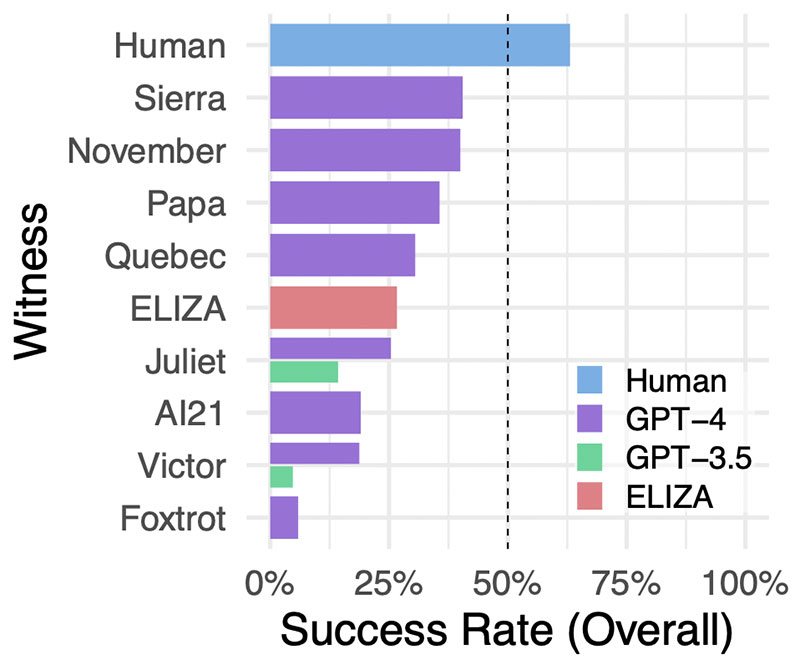
GPT-4 a réussi à tromper l’enquêteur dans 41% des cas, ce qui le place en deuxième position derrière les humains, tandis que GPT-3.5
; ;
en deuxième position derrière les humains, tandis que GPT-3.5
a enregistré un taux de réussite beaucoup plus faible de seulement 14 %. Mais,
comme nous l’avons dit, la surprise vient d’ELIZAqui a réussi
dans 27% des cas en réussissant à tromper l’intervieweur mieux
que le GPT-3.5. Pourquoi parlons-nous de surprise ? Parce que
ELIZA est un chatbot qui est « né » au milieu des années 1960
siècle, par le scientifique du MIT Joseph Weizenbaum.
Le résultat doit toutefois être revu à la baisse en ce qui concerne l’impact qu’il peut avoir
en premier lieu : OpenAI a en effet développé GPT-3.5 spécifiquement
;
pour ne pas se présenter comme un être humain, une raison qui peut donc expliquer
ce qui est ressorti de l’expérience. Et à cet égard, les auteurs de l’étude ont également commenté les résultats afin d’éviter la possibilité d’un être humain ;
Les auteurs de l’étude ont également commenté les résultats afin d’éviter de leur donner une
lecture superficielle : « Tout d’abord, les réponses d’ELIZA ont tendance à être
conservatrices. Bien que cela donne généralement l’impression
d’interagir avec un interlocuteur peu coopératif, d’autre part part, cela empêche le système de fournir des indices explicites ;
empêche le système de fournir des indices explicites tels que des informations incorrectes
ou des connaissances confuses. Deuxièmement, ELIZA ne montre pas le type d’indices
que les interrogateurs sont enclins à associer à des modèles de
grands modèles de langage (LLM), comme le fait d’être serviable,
amical et bavard. Enfin, certains enquêteurs ont indiqué qu’ils
pensaient qu’ELIZA était « trop pauvre » pour être un modèle d’IA actuel
et qu’il était donc plus probable qu’il s’agisse d’un humain intentionnellement inamical ;
collaboratif « .
Le GPT-4 n’a toujours pas réussi le test de Turing
Mais qu’en est-il de l’objectif initial de l’expérience ? Les auteurs
ont conclu, en aval de leurs résultats, que GPT-4 ne peut actuellement pas
peut satisfaire aux critères de réussite du test de Turing puisqu’il
qu’il n’a pas atteint un taux de réussite de 50 % et n’a même pas
dépassé le taux de réussite des participants humains. Selon les
chercheurs, il est possible qu’avec une conception adéquate de l’invite, le GPT-4 et des modèles similaires puissent finalement réussir le test de dépistage de l’alcoolisme et de la toxicomanie ;
l’invite, le GPT-4 et d’autres modèles similaires pourraient finalement réussir le test de Turing ;
test de Turing, mais dans ce cas, le défi consiste à créer des messages-guides
capables d’imiter la subtilité implicite des styles de conversation
conversationnels des êtres humains. En outre, le GPT-4, exactement
comme son prédécesseur, a été programmé avec l’instruction spécifique
de ne pas se présenter comme un être humain. « Il semble très probable que
qu’il existe des messages-guides beaucoup plus efficaces et que, par conséquent, nos résultats
sous-estiment les performances potentielles de GPT-4 dans le test de Turing »,
écrivent les auteurs.
L’expérience a toutefois ses limitescomme le soulignent également ses
ses auteurs eux-mêmes. Tout d’abord, un biais possible dans l’échantillon des participants, dont les adhésions ont été collectées via les médias sociaux, a été identifié ;
participants, dont les adhésions ont été recueillies via les médias sociaux,
et le manque d’incitations, qui a pu conduire certains à ne pas suivre
correctement les instructions données par les chercheurs. Les résultats,
en particulier ce qui est apparu dans le cas d’ELIZA, peuvent être un
élément à l’appui des critiques qui sont régulièrement formulées à l’encontre
le test de Turing en tant que méthode inexacte pour tester
l' »intelligence » des machines. Quoi qu’il en soit, les auteurs de l’étude
pensent que l’expérience peut être pertinente pour
mesurer les interactions sociales et les modes de tromperie, et de
comprendre les stratégies humaines d’adaptation à ce nouveau paradigme.
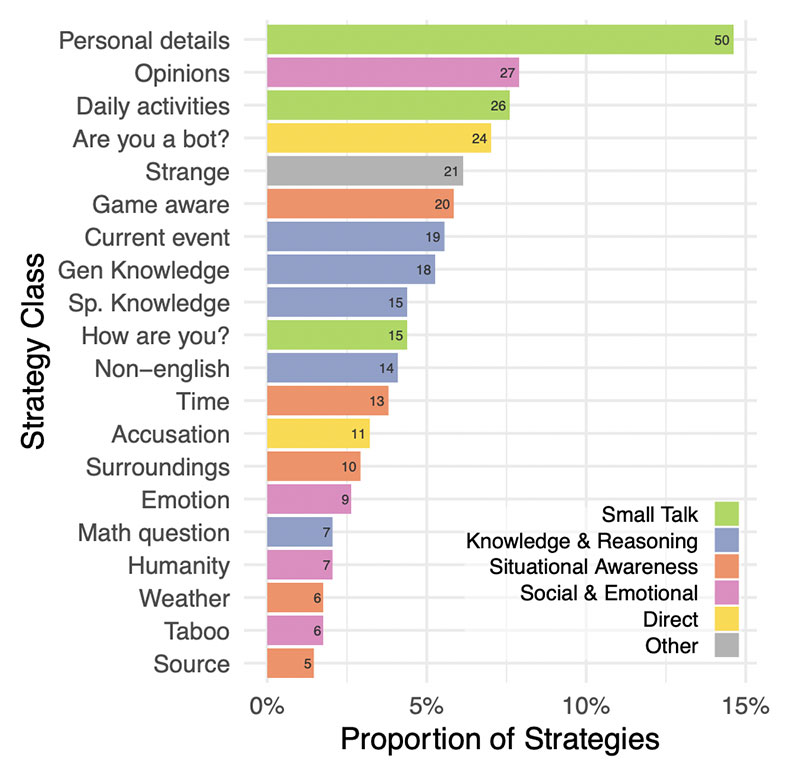
A cet égard, l’étude a permis de rassembler des éléments
des éléments intéressants pour constituer une base statistique des stratégies les plus couramment utilisées par les enquêteurs pour comprendre à qui ils s’adressent ;
les plus couramment utilisées par les enquêteurs pour comprendre à qui ils avaient affaire ;
de traiter. En général, le terrain était préparé pour un discours composé de
de conversations légères et de questions sur la connaissance de l’actualité ;
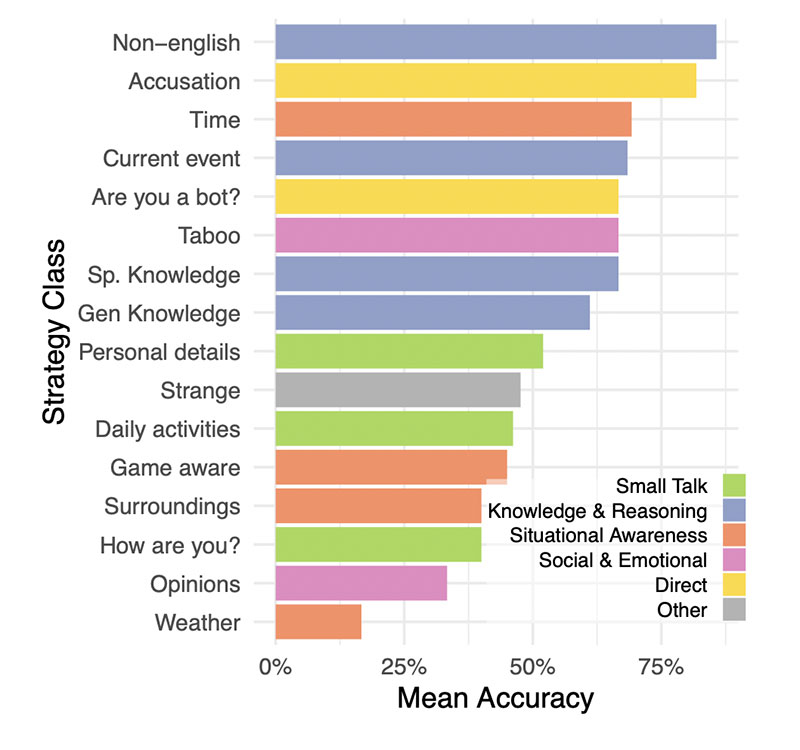
Les stratégies qui se sont avérées les plus efficaces
étaient les conversations en non-anglais, la demande
d’informations sur l’époque ou les événements contemporains et laaccusant
accuser directement le témoin d’être un modèle d’IA.
A partir des réponses reçues, les participants ont ensuite développé leurs
L’expérience a révélé un autre aspect intéressant : les enquêteurs ont basé leurs décisions sur les réponses reçues.
un autre aspect intéressant : les enquêteurs ont fondé leurs décisions
à une écrasante majorité sur le style linguistique et les traits socio-émotionnels
socio-émotionnels qui ressortent des réponses et moins sur la seule
« perception » des capacités intellectuelles présumées ou réelles, comme, par exemple, dans le cas de réponses trop formelles ou trop informelles, ou pas très
par exemple dans le cas de réponses trop formelles ou trop informelles, ou pas très
individuel/personnel et générique. En outre, l’expérience a révélé comment
le niveau d’éducation des participants et leur familiarité avec l’utilisation de
grands modèles de langage n’étaient pas des éléments qui pouvaient
prédire leur succès à détecter qu’ils étaient confrontés à une intelligence artificielle ;
une intelligence artificielle.
Il existe enfin une autre considération concernant les êtres humains qui n ont pas réussi à convaincre d autres êtres humains ;
réussi à convaincre d’autres êtres humains : les résultats dans ce cas
;
peuvent donner des indications sur la nature et la structure du test, plutôt que sur
tout autre aspect spécifique de l’intelligence humaine. Les auteurs
de l’expérience expliquent que certains participants se sont engagés
à « troller », en prétendant être une intelligence artificielle, et que certains
interviewers ont cité ce comportement parmi les raisons qui
les convaincraient qu’ils ont affaire à un être humain. En fin de compte, les résultats des tests pourraient sous-estimer la valeur de l’intelligence artificielle ;
en fin de compte, les résultats des tests pourraient sous-estimer les performances humaines et, à l’inverse, surestimer les performances de l’intelligence artificielle ;
et, inversement, surestimer celles des intelligences artificielles.
L’expérience menée par les deux chercheurs de l’Université de Californie à San
Diego n’est que la dernière d’une série d’études similaires visant à comprendre le degré d’évolution atteint par les IA génératives aujourd’hui accessibles à l’humanité ;
degré d’évolution atteint par les IA génératives désormais accessibles au public et dans quelle mesure le contenu qu’elles produisent parvient à tromper le public ;
public et dans quelle mesure le contenu qu’elles produisent parvient à tromper l’être humain ;
humain. Nous vous avons récemment parlé d’une étude menée par des
chercheurs d’universités australiennes et britanniques, qui montrait que dans les médias, l’être humain a particulièrement du mal ;
l’être humain moyen a particulièrement du mal à distinguer un vrai visage
un vrai visage d’un visage créé par l’IA, vous pouvez la trouver ici : Plus
vrai que vrai : les humains ne distinguent pas les visages créés par l’IA des photographies
vrais.



